Why accuracy alone doesn't work here
ALPINE is built to be errorless: the design keeps her error rate low on purpose, so a single accuracy percentage carries very little clinical information — it saturates near ceiling quickly and stops discriminating between "just met the target" and "flying." Instead of one accuracy number, learning shows up in two complementary ways:
- The support shift. The proportion of her sentence-builds completed with no error-triggered support at all, rising over sessions for a given target. Because our nudges only ever fire in response to an actual mismatch (not on a fixed schedule), this shift is a direct read on her growing independence.
- Fluency past the ceiling. Independent builds per minute, for a target she has already stopped needing support on. This keeps discriminating progress even after the support-shift has maxed out — the same "celeration" idea used in precision-teaching.
The support taxonomy
Every completed sentence-build is classified into exactly one of four levels, derived automatically from her taps — nothing extra for her to do, nothing visible to her.
| Level | What it means | Counts toward advancement? |
|---|---|---|
| L0 — independent | No nudge ever fired, no reselection. A clean, unprompted build. | Yes — the criterion metric |
| L0b — self-corrected | She changed a tile before finishing, but no nudge ever fired. Shown as its own signal — an emerging-mastery sign — but kept separate. | No — displayed, not counted |
| L1 — visual nudge | At least one gentle "look again" nudge fired for a tile that didn't fit the grammar rule. | No |
| L2 — prompt redirect | At least one photo-mismatch redirect fired (the sentence didn't match what's in the photo). | No |
Only true L0 builds count toward the advance criterion below — L0b is deliberately excluded from that math, even though it is displayed, because a self-correction still involved an internal mismatch worth seeing separately from a fully anticipatory, unprompted build.
The advance criterion — evidence, not a verdict
The default reference criterion is about 90% independent (L0) builds across three sittings, on at least two distinct days. It is deliberately labeled a reference, not a rule: every threshold — the percentage, the number of sittings, the day-spread requirement — is configurable by the SLP for this learner. The figure traces back to a small published study (N = 3 children); that population caveat is displayed alongside the criterion everywhere it appears, not buried in a footnote.
A sitting is derived automatically, not hand-logged: it's the longest run of activity where no gap between events exceeds 30 minutes (also SLP-adjustable). This keeps "three sittings" meaningful even though the tablet is used in short, irregular bursts rather than scheduled clinical sessions.
The evidence table
The dashboard's central artifact is a per-target evidence table. Every row names what the data bears on — never what to do about it — and every figure shows its raw denominator so a small sample is never dressed up as a strong signal.
| Metric | What it shows | What it's evidence for | Minimum data |
|---|---|---|---|
| Independent rate | % of builds at L0 (L0b excluded), this session and last three sessions | Advancement, against the SLP's criterion | ≥5 builds/session |
| Support-shift trajectory | %L0 vs %L0b vs %L1+L2, per session, over time | Fading or adjusting support | ≥5 builds/session |
| Fluency rate | Independent builds per minute, within a session | Progress past the accuracy ceiling | ≥3 builds |
| Trials-to-criterion | Builds needed until criterion is first met | Teaching efficiency; comparing conditions | n/a |
| Cold-probe rate | Each session's first build on a target, treated as a natural probe | Regression flag; maintenance evidence | ≥3 probes |
| Error anatomy | Which grammar rules and tile choices trigger support, from the tap record | What to re-teach or emphasize next | ≥3 support events |
| Self-correction rate | L0b / (L0 + L0b) | Emerging-mastery nuance (display-only) | ≥5 builds |
| Side-bias check | Tile position chosen vs. correct position, per column | Guessing alert | ≥20 taps/column |
| Abandonment | Builds started but never finished, and where in the session | Engagement | ≥10 builds |
Rows phrase results as evidence ("9 of 10 independent, last 3 sessions; criterion reference 90%×3") — never as a readiness or regression verdict. Below the floor, the dashboard says so plainly: "insufficient data" rather than guessing.
The dashboard
The dashboard is the guardian- and clinician-facing view of everything above: a session log, a per-map view, and the export tools described below.
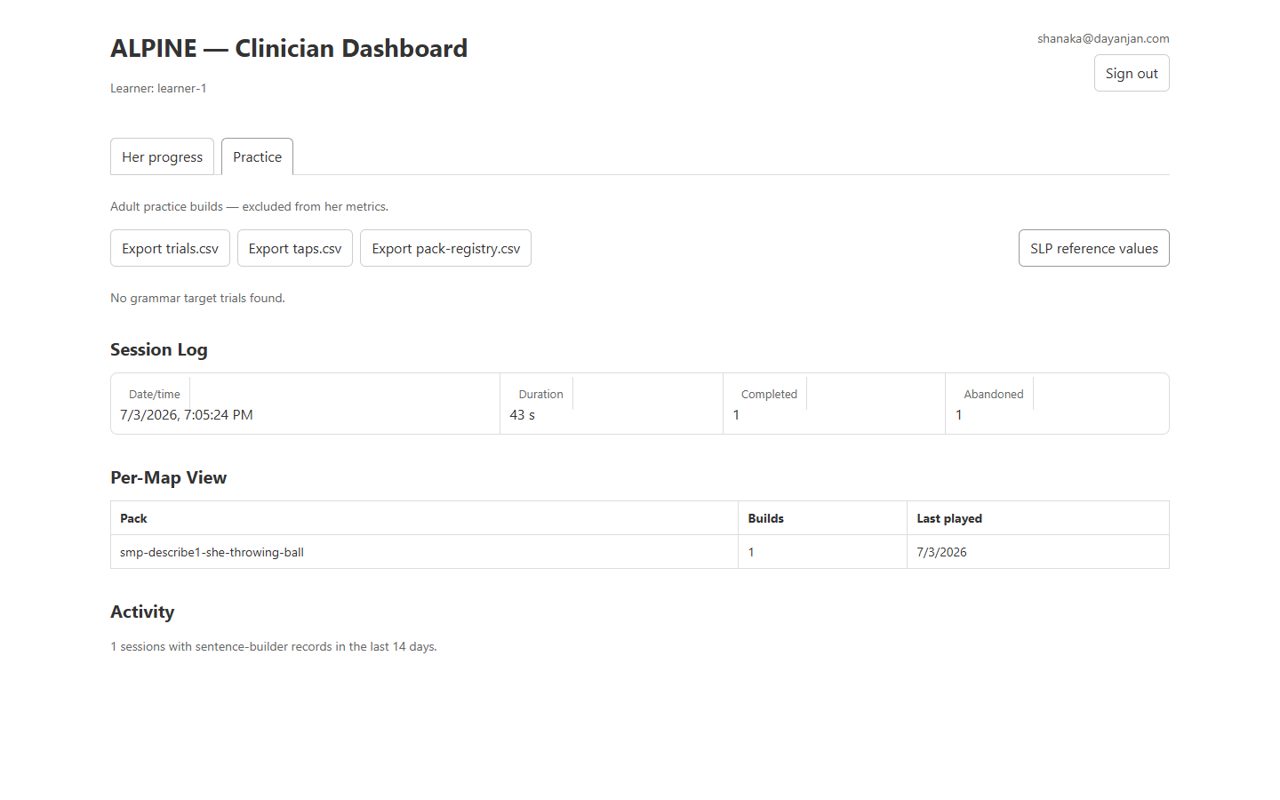
The CSV exports
Every trial is captured as detailed tap-by-tap telemetry, invisible to her and free of any extra step on her side. The CSV exports are the primary clinical artifact — built so an SLP can bring the data into her own tools rather than being limited to our charts.
| Export | Grain | Contains |
|---|---|---|
| Trials | One row per sentence-build | IDs and timestamps, pack and target, support level (L0/L0b/L1/L2), error anatomy summary, condition stamp, cold-probe flag, sitting membership. |
| Taps | One row per tile tap, long format | Timestamp within trial, slot and tile identity, position in column, reselection flag, feedback fired (continue / look-again / prompt-mismatch / reward), and any rule violated. |
| Pack registry | One row per pack version | Slots, choice sizes, distractor classes, grammar targets, and sentence length — joined against trials so a condition or pack change is always interpretable in context. |
The one chart the dashboard always shows is a per-target time series: percent independent (solid line), percent self-corrected (dotted), percent supported (muted), with phase markers at any pack or map change and cold-probe points overlaid — no smoothing, no cumulative tricks.
What the app deliberately does not do
A short list of anti-metrics commitments, held on purpose:
- No overall accuracy headline
- No mastery badges
- No cross-target score
- No auto-advancement
- No camera, gaze, or affect capture
- No learner-visible metrics
- No third-party analytics
The app reports. The clinician judges.
All data belongs to the family: single-tenant storage, indefinite retention until the family deletes it, access limited to one account. Every criterion default is SLP-configurable, and every population caveat behind a default (like the N = 3 study behind the 90%×3 reference) is shown alongside the number, not hidden.
Episode 3
The adult side: practice mode, packs, advancing maps
Episode 5